
DeepSeek-R1 (Nature Version) – Notes
Published:
Yesterday, I spent some time reading the Nature version of the paper on DeepSeek’s R1. Compared with the globally sensational arXiv version released on January 22 this year, there are many details worth interpreting. Below are my thoughts:
① Key Insight — Why R1 Improves at Reasoning
First, let me share a point that made me “suddenly enlightened” after reading: the Nature version provides a more concrete explanation for “why R1 suddenly became stronger in reasoning tasks”.
I went through the training process from start to finish, and the most intuitive impression – which also breaks the perception of many in the academic community – is that R1’s improvement is not due to “pure RL magic”, but to a deliberately segmented engineering process. In the early stage, R1‑Zero used rule‑based verifiable rewards to train “long thinking time” (the graph also shows the inflection point between “aha moments” and the frequency of the word “wait”). However, its output was rough and prone to mixing Chinese and English. In subsequent versions, instead of continuing to rely solely on RL, the team returned to SFT to supplement the data distribution, adding substantial non‑reasoning and software‑engineering data. This explains the increase in code and writing‑related metrics. Among the ~800k SFT samples, ~600k are reasoning and ~200k are non‑reasoning, and the latter includes engineering data (e.g., program repair and front‑end development) — aligning with my intuition about the coding gains.
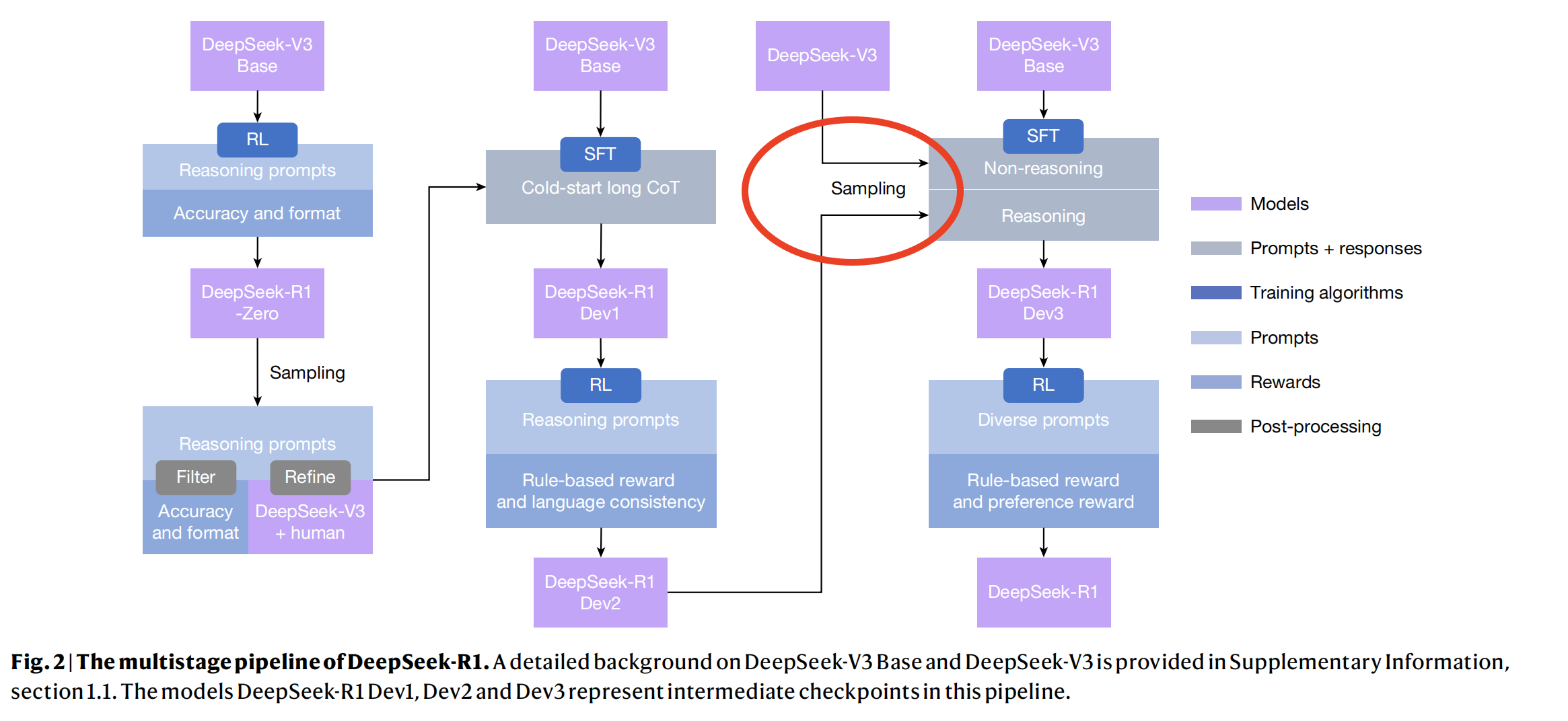
② Multistage Pipeline — Zero → Dev1 → Dev2 → Dev3 → R1
My understanding process started with figuring out what Zero learned, then identifying “what improvements were added at each stage”, and finally understanding how R1 was ultimately achieved. In general, during the Zero stage, with pure rule-based rewards and signals that only focused on final correctness, the model naturally developed behaviors like “reflection/verification/multi-path attempts” along with longer output lengths for code and math tasks. However, Zero had issues with readability and language consistency, and was not friendly to general instruction scenarios. Therefore, Dev1 used a small amount of Zero’s data, which was polished and rewritten using DeepSeek V3 to create “long CoT cold start” and instruction data, thereby improving readability and instruction-following ability. But this also led to a decline in scores for some strict reasoning tasks. Dev2 then used reasoning-focused RL again to boost performance in math and coding. What’s noteworthy about Dev3 is that it abandoned all previously trained model checkpoints (CKPTs) and restarted with the most basic base model, DeepSeek-V3, to perform SFT on both reasoning and non-reasoning data simultaneously, which further improved performance in general writing and engineering tasks. Finally, R1 underwent a round of “hybrid rewards + preference/safety” tuning to wrap up the process. Scores for code and math tasks only saw minor adjustments, but metrics related to “user preference/comprehensive writing” (such as AlpacaEval and Arena-Hard) showed the most significant increases. The narrative of “stage – highlight – trade-off” is very clear in the Nature version. My reading experience was that each stage addressed the problems left by the previous one, and the counter-mainstream, counter-intuitive method of using intermediate models only for self-distillation (which makes one feel that SFT alone can play a significant role) was quite striking.
③ Observations
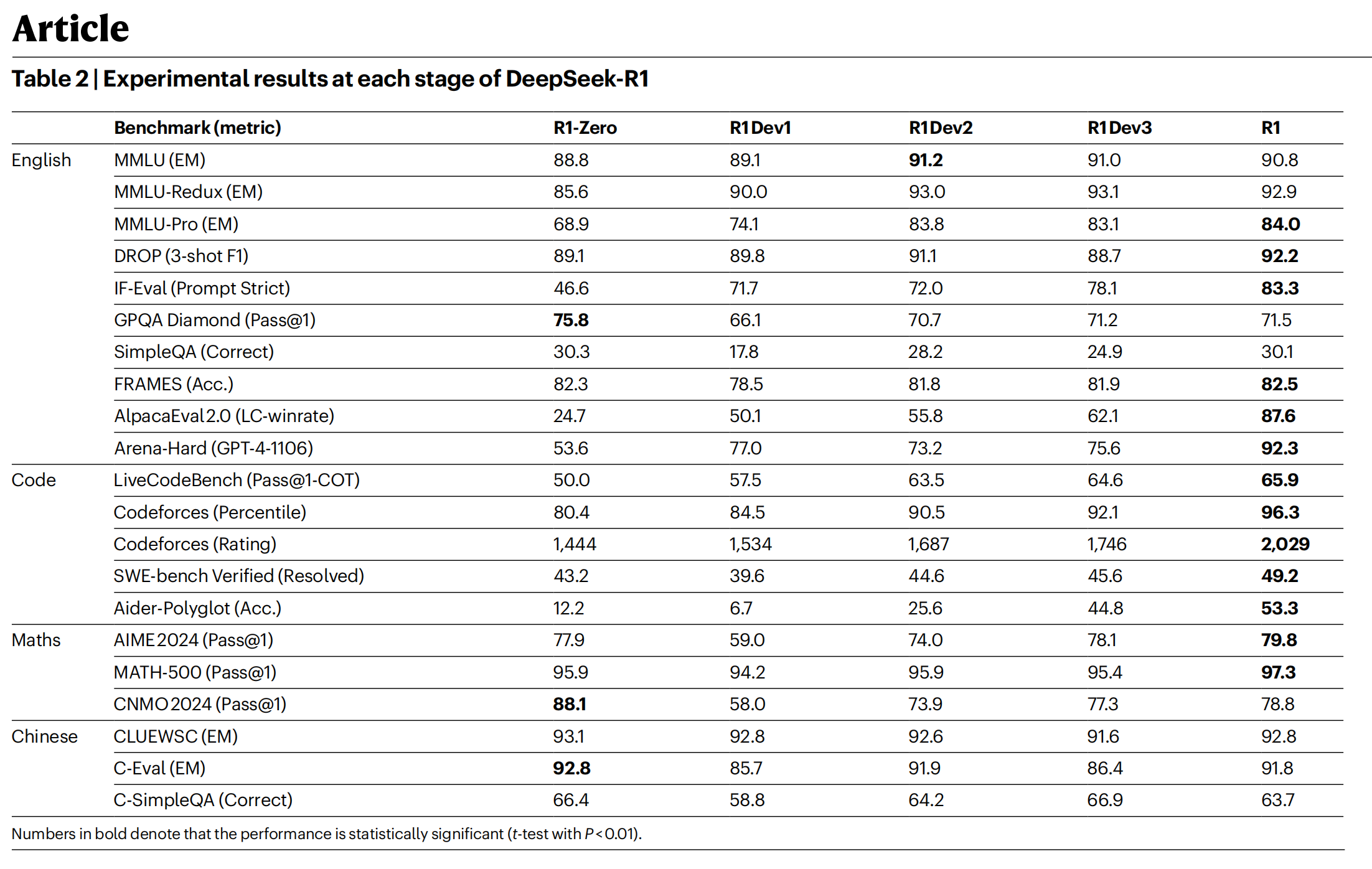
When analyzing the performance scores on reasoning datasets, I found that the Zero version achieved relatively high initial scores on multiple tasks. For math-related datasets such as AIME, MATH, and CNMO 2024, its scores were even higher than those of the subsequent Dev2 and Dev3 versions. Taking AIME as an example, the Zero version had a good score at the beginning, but when Dev2 entered the RL stage, its score dropped instead. I speculate that this may be related to the change in the reward function during the Dev2 stage – the authors modified the reward function to “language consistency + rule-based”, and this adjustment may have weakened the model’s pure reasoning ability. However, in the Dev3 version, after mixing Dev2’s data with instruction-following data, AIME’s score rebounded slightly. I think this is because the instruction-following data improved the model’s comprehension ability, which indirectly supported the reasoning tasks. In the final R1 version, after SFT and RL training, the overall score increased, but it still did not exceed the score of the Zero version on AIME.
Looking at the two math datasets MATH and CNMO 2024, the Zero version still had the highest scores. Subsequent versions saw a decline in scores due to the addition of SFT or adjustments to RL objectives. This made me think: perhaps math tasks do not require natural language assistance. The Zero version was not disturbed by natural language-related objectives (such as format requirements and instruction following), allowing it to focus more on mathematical abilities, hence its better performance. In contrast, later versions had to balance the need to “produce human-like language”, which distracted them from mathematical reasoning and led to impaired performance. I even think that if we train math models using pure symbols instead of natural language, we might achieve better results.
④ Future Work I could think of from this paper
Breaking through the limitations of rejective sampling: The current model uses rejective sampling, which relies on known answers. It is only applicable to tasks with clear correct results and cannot be used for open-ended problems or fields with unknown answers. In the future, we need to explore sampling and training methods suitable for open-ended tasks, reduce reliance on “known answers”, and improve the model’s applicability in real-world unknown scenarios.
Optimizing the model’s adaptability to few-shot prompting: Experiments show that DeepSeek R1 is sensitive to few-shot prompting – its performance even decreases when such prompts are added, which is quite counter-intuitive. In the future, we need to study the underlying reasons (e.g., the high proportion of single prompts in training data, insufficient context understanding by the model) and adjust the training data structure (e.g., increasing few-shot samples) or optimize the model’s context processing logic to ensure the model maintains or improves performance in few-shot scenarios.
Exploring the application of “pure symbolic training” in math and coding tasks: Math and coding tasks do not rely on natural language. Currently, models integrate natural language capabilities (such as instruction following and format requirements), which instead weaken their performance in these two types of tasks. In the future, we can try training models from scratch using pure symbolic data, explore task-specific models that do not depend on natural language, and verify their performance limits in math and coding tasks.
Transferring DeepSeek’s training method to Deep Research tasks: I think it must be insteresting if we apply the process of “first using RL to obtain verifiable rewards → generating intermediate traces for SFT → model self-distillation via Reject Sampling → mixing instruction-following data for distillation → further RL” to Deep Research tasks (e.g., generating reports with verification points, Browsecomp). We will design task-specific reward functions based on the characteristics of these tasks and verify the effectiveness of this method in complex, verifiable tasks to break through the performance bottlenecks of existing Deep Research models.
⑤ Issues in the Paper That Could Be Improved (Welcome to Correct Me If I Am Wrong)
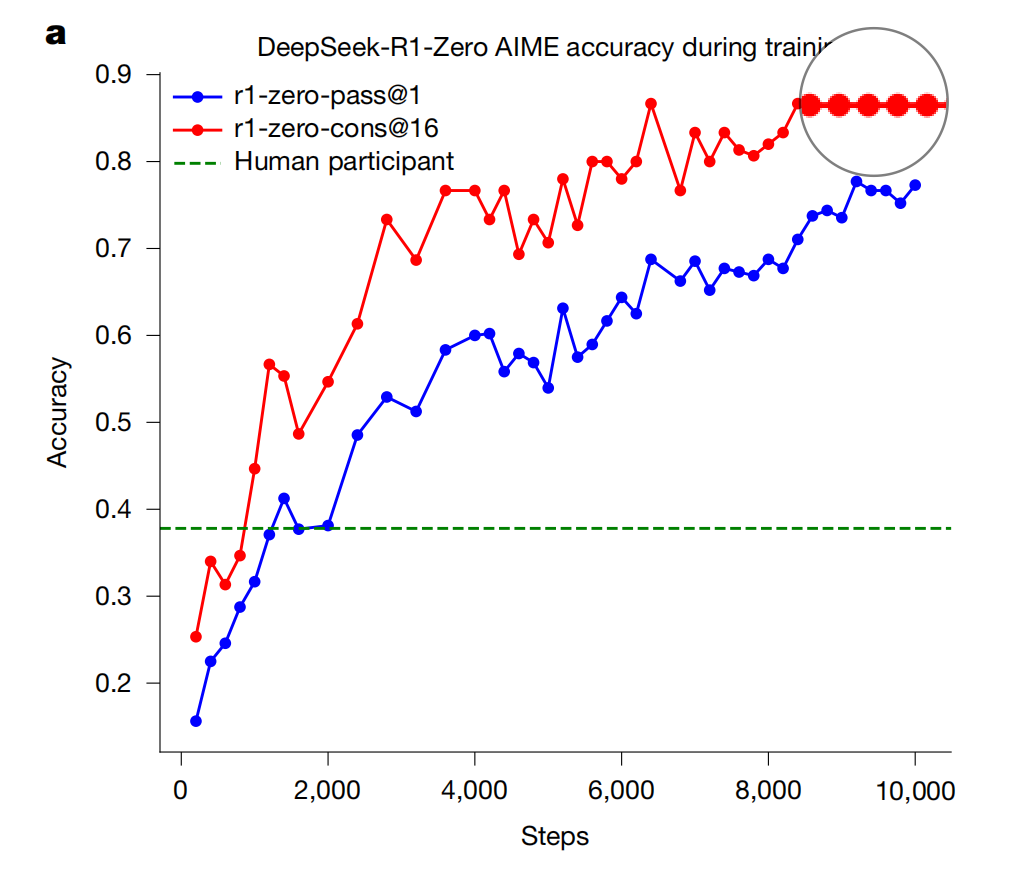
Doubts about the rationality and authenticity of charts: Some charts seem problematic. For example, the end of the red line in the left graph of the AIME training curve is flat. I speculate that this part was artificially extended to “align with 10,000 steps” with other curves, rather than being a real training result (the real training process might still be fluctuating or rising slowly). This is because the original arXiv version only covered up to 8,500 steps. Moreover, the basis for this adjustment is not explained, and there is a lack of data support, which affects the credibility of the charts.
Inaccurate description of “pure RL methods”: The paper claims that DeepSeek R1 uses “pure RL methods”, but the model actually includes a large number of intermediate SFT processes (e.g., mixing data for SFT in the Dev3 stage, intensive SFT before the final R1 version) and abandons many previous CKPTs. At most, it can be described as a hybrid method of SFT and RL (and from the perspective of the training process, SFT accounts for a much larger proportion). This description contradicts the actual training process and is likely to mislead readers’ understanding of the model’s core method.